
Step 1 — Software Estate Audit (30–45 days)
Most companies don’t have a “software problem.” They have a software sprawl problem: one-off tools, duplicated logic, brittle integrations, and tribal knowledge.
We map your software estate into a single, CEO-readable view:
- What exists (apps, scripts, automations, dashboards, spreadsheets-with-a-budget)
- What it costs (cash, time, risk, delays, opportunity)
- What breaks (where work stops when one person is out)
- What repeats (the “same 95%” built again and again)
Deliverable: an executive brief + a prioritized backlog with ROI and risk.
Step 2 — Stabilize the Foundation (Stop the bleeding)
Before building “new,” we eliminate the silent drains:
- unreliable deployments
- missing environments
- no ownership model
- mystery integrations
- unknown data flows
We add the basics that prevent rework:
- environments you can trust (staging/preview where it matters)
- monitoring and failure signals
- a “known-good” release process
- a decision log (so future teams understand why)
Outcome: fewer emergencies, fewer regressions, fewer “we’re afraid to touch it” systems.
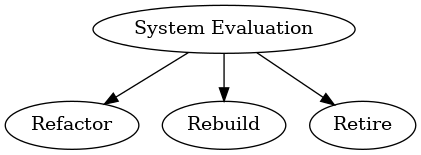
Step 3 — Refactor, Rebuild, or Retire (with clear decision rules)
One-off systems usually die in one of three ways:
1) they get endlessly patched
2) they get rewritten from scratch (again)
3) they become an accidental product no one owns
We run a simple decision framework:
- Refactor if the system is structurally sound but messy
- Rebuild if the system can’t be safely evolved
- Retire if the system never produced ROI (or no longer needs to exist)
Deliverable: a documented call with cost/risk/benefit, not opinions.
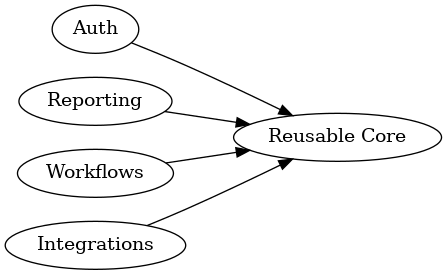
Step 4 — Productize the “Common 95%” (Reuse instead of re-building)
A surprising amount of internal software is the same ingredients:
- identity + roles
- approvals + audit trails
- CRUD + search + export
- reporting + scheduled jobs
- integrations + pipelines
- admin panels + ops tooling
Instead of recreating these every time, we turn repeatable patterns into reusable building blocks (and, when appropriate, marketable tech).
Outcome: your next internal tool is 30–60% faster to deliver because the last one wasn’t wasted.

Step 5 — Stewardship Operations (Continuous improvement, not “project completion”)
Most agencies deliver code and disappear. That’s how one-off tools become liabilities.
We operate like a long-term steward:
- roadmap alignment (what matters this quarter)
- reliability and performance tuning
- cost control (especially repeat infra/token waste)
- documentation upkeep (kept current, not ceremonial)
- incident response + postmortems + prevention
Outcome: the tool stays valuable after launch — and improves over time.

Step 6 — Continuity & “Keeper of Keys” (Survive turnover and layoffs)
Layoffs don’t just remove headcount — they remove:
- system context
- undocumented decisions
- access keys
- integration knowledge
- the “one person who knows why it’s like that”
We become the continuity layer:
- a maintained architecture repository
- controlled access & key custody procedures
- onboarding documentation for new teams
- dependency maps and runbooks that actually work
Outcome: your software remains operable and understandable through org churn.
What you get when the systems are stable and understood
- Less rework and fewer repeated builds
- Faster delivery without “mystery risk”
- Lower key-person dependency
- Better ROI from the software you already paid for
- A clear path to turn internal capability into reusable assets
If you want a starting point:
Start with the Software Estate Audit. It’s the fastest way to turn “we have a lot of code” into “we know what we own, what it costs, and what to do next.”